
Income and IQ - Finnish Data
New data adds a wrinkle to the case

We’ve seen Danish data, we’ve seen Swedish data, we’ve seen American data, and now we’ve got Finnish data. With all the data in, we can confidently say it: IQ and earnings are related, and the relationship is pretty large and pretty similar in Scandinavia and America. But in one respect, the Finnish data looks more like the Danish and American data than it does the Swedish data. Specifically, the Swedish nonlinearity doesn’t hold in Finland. Let’s take a look:

As a reminder, here’s the Swedish graph:

They’re very similar, but the Swedish data has been interpreted in favor of nonlinearities at either extreme. The Swedish data also showed a curious distribution of maxed out scores:

But the Finnish data shows about what you’d expect:
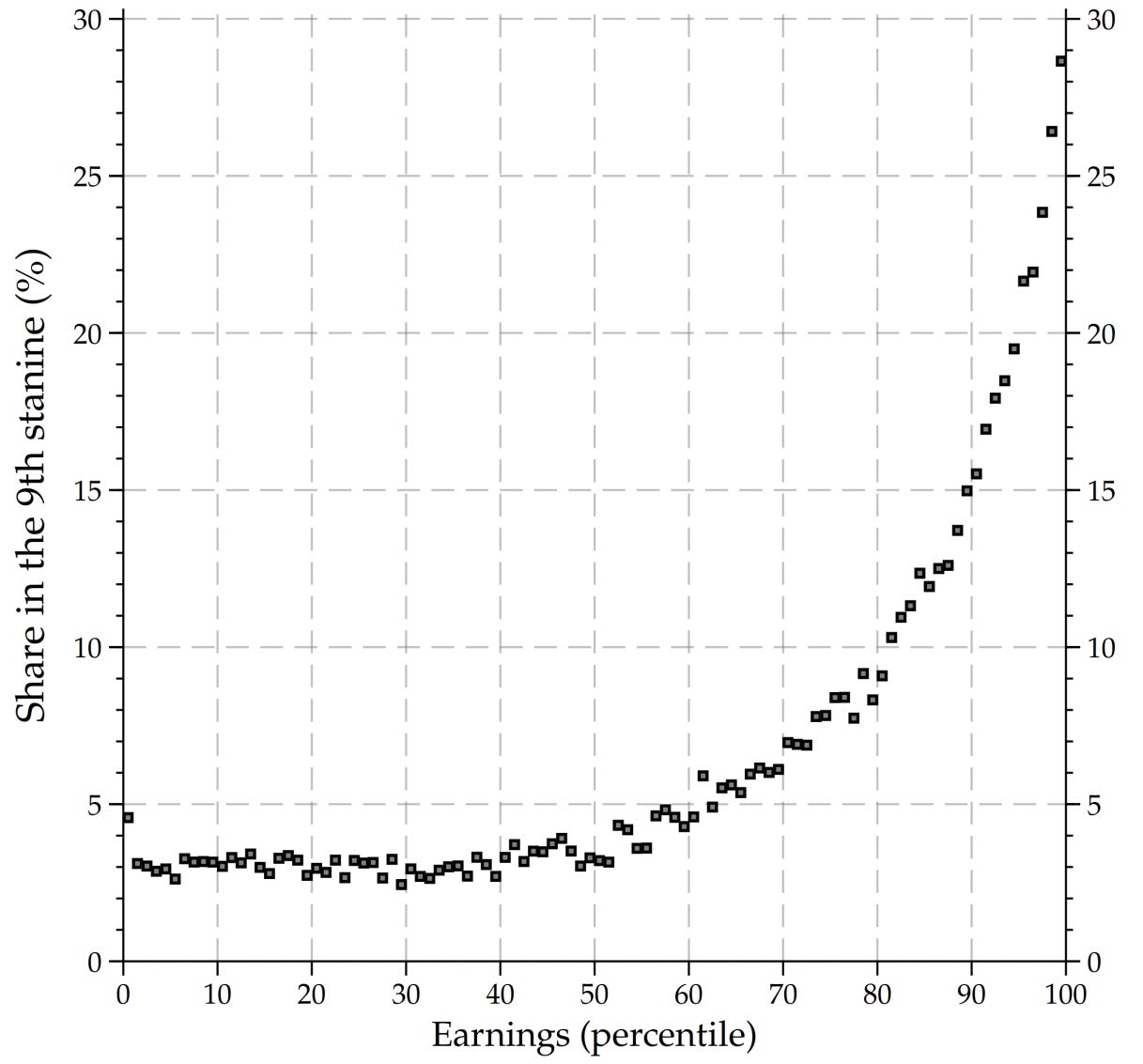
What’s going on? The question remains unanswered, but there are a few explanations worth pursuing prior to chalking this up to Sweden being unique. First, is this effect driven by data coverage? In the Finnish data, we know that there are people omitted from the registry because of low cognitive ability, which may be biasing. Is the same or something different true in Sweden? In the American and Danish data, it is not, but the American data is extremely small by comparison and the Danish data hasn’t been presented like the Swedish and Finnish data.

Second, is this effect driven by reliability? A simulation I ran and a paper I linked in my last post on this subject suggest the answer could be yes, and several factors like binning could have made this more likely, but by no means guaranteed. Ranking the cognitive tests in the different datasets, the American is the best, followed by the Finnish, then the Danish, and finally by the Swedish. The Swedish cognitive test is a bit less reliable than the rest and the data available suggests the Flynn effect on it may be severe for the sample used in the original income-IQ paper, suggesting the reliability could have fallen accordingly, if only due to the resulting range restriction. But, the Swedish test still seemed to produce practically the same aggregate correlation between scores and earnings as we look to get in Denmark, the U.S., and Finland. As a reminder, the correlation (ρ) between IQ and earnings was 0.40 in Sweden and 0.46 in America and we don’t have the exact numbers for Denmark or Finland, but their results all look quite similar. Unreliability will tend to attenuate correlations, but it has even more substantial effects at the tails, which is where inference in the Swedish study was concerned.
Addressing the issue of reliability is simple, and the Finnish study may have contributed a first data point with this chart:

Providing breakouts of each of the subtests is useful because each of the subtests should be less reliable than their composite. The issue now is that the reliability differences may not be very large, so this possible adverse effect of unreliable tests may not be reproduced with so simple a method. The ideal thing to do is to find a large dataset with many items available for analysis and to produce composites with varying levels of internal reliability (or ideally, retest reliability), and to then assess whether making the test less reliable can reasonably often reproduce the pattern observed in the Swedish data. Nudging the results by applying an unusual stanine transformation is an allowable part of the exercise.
In the NLSY data I used, there’s simply not enough power to do this. The various subtests in the NSLY do have varying numbers of items, but the correlation between their reliabilities and the number of items in each of them wasn’t great enough to make a difference at ρ = 0.271. Items are available for four subtests in the NLSY ‘79 and the ‘97 each, but again, the sample sizes are too small for a meaningful randomization test. But here are the results by the NLSY’s ASVAB subtests anyway:

As an added note, the correlation between subtests’ g-loadings and their reliabilities was effectively 0 (ρ = 0.073), the correlation between subtests’ reliabilities and their correlations with income was ρ = 0.409, and the correlation between subtests’ g-loadings and their correlations with income was ρ = 0.709.
Because I don’t have the required sample size to do much more, someone else will have to see if data coverage problems or reliability issues are explanatory.
There may be other artefactual explanations for Sweden’s oddness compared to other countries with available data, but if some initial, plausible ones are tested and they’re found wanting, substantial speculation can rightfully begin. Until then, we can simply assume the Swedish result1 is odd, rather than representing a result in need of explanation, much less in need of an explanation attributing it to something unique about the Swedish economic environment.
Which I showed in my other post relies on a difference with a p-value of 0.04 for its conclusions about Sweden’s elite earners’ and an alleged high-ability plateau.
Project talent should be large enough to do this but you need the private follow up data to get income in adulthood.
>IQ and earnings are related, and the relationship is pretty large and pretty similar
I think this is still not impressive. For example, how many times does a person with an IQ of 145 earn more than a person with an IQ of 100? 2 or 3?