
WEIRD Doesn't Work
Identifying moderators of psychological effect sizes is more complicated than simply pointing at demographics

The samples used in psychological studies are overwhelmingly “Western, Educated, Industrialized, Rich, and Democratic” or “WEIRD.” They come from Europe, America, the Antipodes, and maybe Japan and Korea, and they’re usually made up of university students. So, argued Henrich, Heine and Norenzayan (HHN) we have a problem: if psychology is to be a science of the human mind, we have to make sure we’re not simply talking about the minds of well-off Westerners.
Per HHN, the “WEIRD” constitute a small fraction of the global population but they make up the overwhelming majority of the samples used in psychological studies. What if, they contend, the WEIRD differ in ways that make it hard to generalize findings from them to the rest of the human population? Then we need to diversify our samples of course!
But pace. HHN provided descriptions of WEIRD samples and explained that they’re different in many observable ways from non-WEIRD samples, but they didn’t show that those differences matter: HHN didn’t show that WEIRDness impacts the replicability or magnitudes of psychological effects. If WEIRDness doesn’t matter, then we shouldn’t worry about WEIRDness. So does it matter?
Hypothetical Moderation
After reading through papers on the issue of WEIRD sampling, I’ve noticed that different authors provide very different levels of sophistication in how they think about the supposed problem. The general schema from lowest to highest sophistication is like so:
BAD: “WEIRD samples are demographically different from the global norm. This is a problem for psychology.”
Not As Bad: “WEIRD samples are demographically different from the global norm. This might be a problem for psychology.”
Mediocre: “WEIRD samples are psychologically different from the global norm in terms of variables like personality and attitudes. This is a problem for psychology.”
OK: “WEIRD samples are psychologically different from the global norm in terms of variables like personality and attitudes. This might be a problem for psychology.”
On Track: “WEIRD samples exhibit different behaviors from the global norm in experimental settings. This is a problem for psychology.”
Alright: “WEIRD samples sometimes exhibit different behaviors from the global norm in experimental settings. This might be a problem for psychology.”
Reasonable: “WEIRD samples sometimes exhibit different behaviors from the global norm in experimental settings, but the extent of the problem hasn’t been differentiated from what you would expect due to chance. WEIRD-related group differences might be a problem for psychology.”
The reason most views on WEIRD sampling are bad is that they presuppose a problem without justifying the belief in the problem. Let’s go up the ladder.
In the original HHN work on this, they definitely indicated that WEIRD samples differ from the broader human population demographically. They did not show that this demographic variation drives differences in the results of psychological studies between WEIRD and less WEIRD or non-WEIRD samples.
In the original HHN work on WEIRD populations (and later work), HHN provided some evidence that the mean psychological trait levels of WEIRD samples differs from the mean psychological trait levels of the wider non-WEIRD world. There are publications indicating differences in things like Big Five response levels and patterns, IQs, attitudes, and much else, but there’s no a priori reason to believe that these differences actually matter for psychological research by altering experimental treatment effects or isolating the responses to quasi-experimental exposures to certain populations. More importantly, the evidence for differences in these variables is often very bad. Consider Lukaszewski et al.’s paper on differences in the Big Five traits across 55 different countries. They couldn’t achieve configural invariance across countries. Their model CFIs were either literally zero (Agreeableness, Neuroticism/Emotional Stability) or 0.25 (Conscientiousness, Extraversion, Openness). There’s no way to use this data to conclude anything about differences in the levels or structures of personalities across nations, much less to indicate anything about how those differences might impact real-world behaviors, treatment effects, and so on.
In the original HHN work on WEIRD populations, they provided some evidence that WEIRD populations behave differently in games, might have some different treatment effects, and so on. But these studies were not systematically reviewed, nor were they strong evidence of generalizable issues. Systematic investigations of this issue have actually not been undertaken despite the WEIRD issue being around for more than a decade now. The closest thing we have comes from the Many Labs 2 replication effort.
In Many Labs 2, a long list of authors across 36 countries and territories looked into 28 classic and contemporary psychology studies that seemed like they should be easy to cheaply replicate. This study sampling means they are not necessarily representative of psychological effects more generally, but reassuringly, the effects are very diverse. The point of this study was less to investigate particular effects’ replicability, and more to investigate the impacts of sampling and study settings on replicability. In an exploratory analysis of the 28 effects’ replicability across more and less WEIRD samples, the result was—drumroll—limited WEIRD-related heterogeneity:

Three of the 28 effects showed significant moderation by WEIRDness after correction for multiple comparisons (can you even visually tell which ones they were?), and the one by Norenzayan et al. (“Intuitive Reasoning”; Norenzayan is the ‘N’ in ‘HHN’) saw significant moderation in the opposite of the direction initially found by Norenzayan et al. This means that, rather than what Norenzayan et al. initially saw—that Asians (the less WEIRD) use intuitive reasoning more than Europeans (the more WEIRD) do—the Many Labs 2 crew saw that WEIRDer populations used intuitive reasoning more. In this sense, the finding was a replication (WEIRD moderated the effect size) and a replication failure (WEIRD moderated the effect size in the opposite of the original direction).1
Now, this is not to say that WEIRD is not an important effect moderator in psychology, it’s to say that we don’t know if it is, and we have some alright evidence that our prior should be it’s not. Being WEIRD might matter a lot in some domains, but my guess it that will tend to be more true the worse the measurement is. The reason for this is that there are plenty of opportunities to severely mismeasure variables between cultures, but human universals should be more common than major group differences given our species’ common evolutionary past. Here’s a simple example: Give an English-speaking group and a Twi-speaking group English language questionnaires and watch the results correlate with different things across cultures. If you immediately think this is due to ‘WEIRDness’, then you’re missing the more obvious position that this is due to measurement bias and your result doesn’t give you any idea if WEIRDness actually psychologically impacts response patterns because the questionnaire responses don’t mean the same things for the English and Twi speakers and you don’t know how comparable they are or why they might not be comparable.
Stop Premature Calls to Action
Psychology may be insufficiently diverse, psychology might need to become less American, and the fact of psychology—the field’s—sample WEIRDness might be enough to motivate a “call to action” to diversify the field’s samples. But we shouldn’t assume that ‘lacking’ diversity actually matters until we’ve tested that it does. And by testing it, I mean really testing it. It’s not enough to find differences between groups in one-off studies or in biased psychological trait and attitude measurements: we need to see systematic evidence of differences in experimental effects before it’s appropriate for a “call to action” to diversify samples.
A better-supported call to action would focus on making sure that we have instruments that can be used to provide valid comparisons of more and less WEIRD populations, making sure we have samples large enough to test for interactions with WEIRDness, and systematically investigating whether effects that we know replicate in WEIRD and non-WEIRD samples for understandable reasons replicate across samples with varying levels of WEIRDness. Anecdotes are not an appropriate basis for a cumulative scientific enterprise, so the fact that plenty of people have seen one- or few-offs where WEIRDness seems to matter should not be used to call for action that might not be necessary or useful for the field to pursue.
Convenience Sampling Has Been Unfairly Maligned
Many of the people who have written about the problem of “WEIRD” sampling have taken it for granted that convenience sampling leads to biased, unrepresentative results. While it might be true sometimes that convenience samples lead to replicability or generalization issues, that’s not a given. In reality, convenience sampling is only conditionally bad. In fact, a few years back, this was given some systematic investigation that suggested we really shouldn’t be so harsh.
Coppock, Leeper and Mullinix sought to replicate 27 different survey experiments that were conducted on nationally representative samples using conveniently available Amazon Mechanical Turk samples. Across the sorts of surveys they looked at2, differences in effect sizes from the original experiments were pretty minimal!
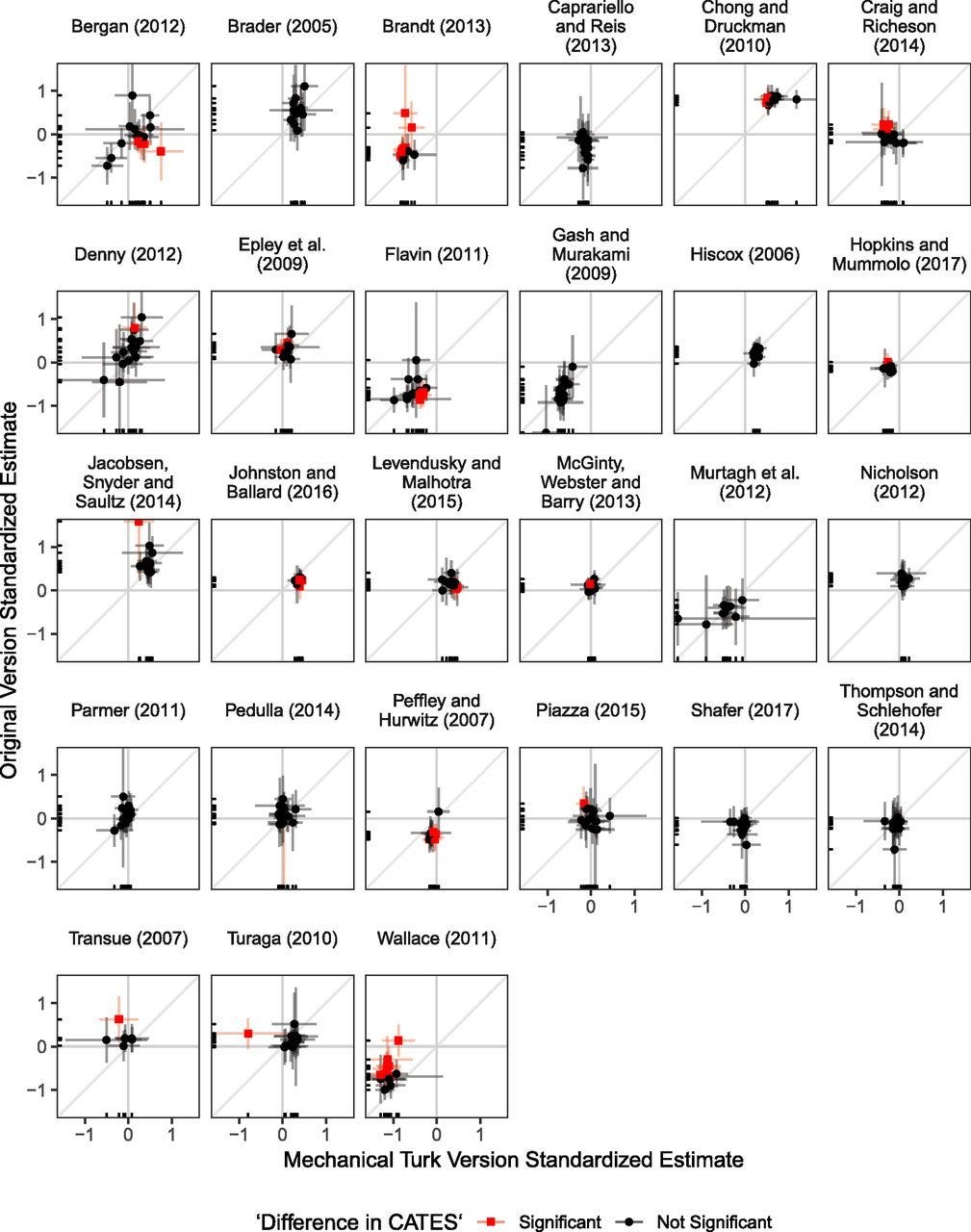
Going even further than this, many commonly-proposed moderators also failed to yield consistent evidence for impacts on observed effect sizes. For example, education, age, sex, race, and politics played only limited roles in treatment effect heterogeneity.
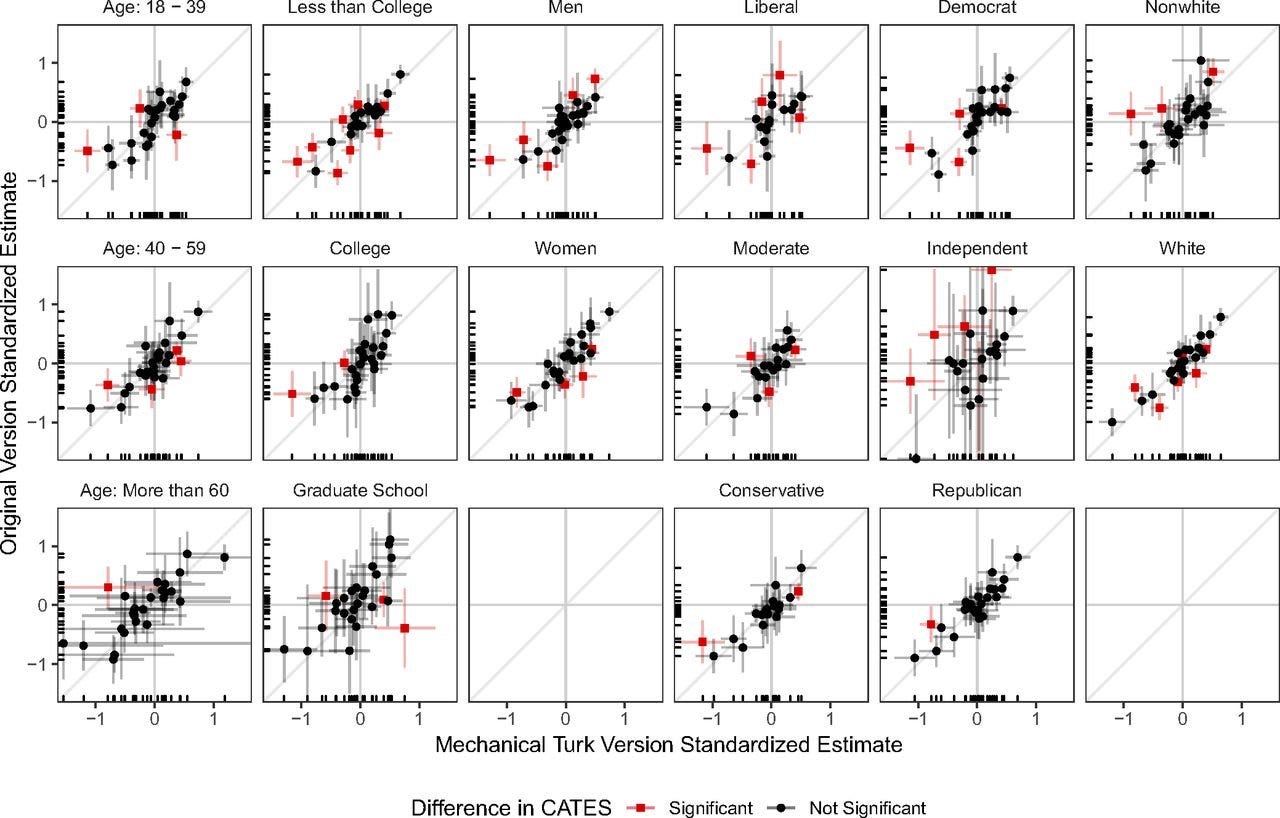
All of this is not to say that sample heterogeneity doesn’t matter, but instead to say that we cannot take for granted that it will matter in any given scenario. Until we appreciate this fact, we’re going to keep seeing people eliciting calls to action that might end up being little more than calls to make psychological research more expensive.3
See the Many Labs 2 footnote 5 for more clarification on the exact differences with the original Norenzayan et al. study’s findings.
Keep this key qualification in mind.
After posting this, I was sent two additional studies on the topic. The first looked into experimental result stability across many different groups and found that results were generally stable, but there was some instability comparing the U.S. and India. The second showed that people are averse to changing people’s ranks even if they’re also averse to inequality, finding that this preference practically holds up across societies, with nomadic Tibetans being a particularly likely to show this preference.
Overall, these two studies did not find evidence of a large WEIRD issue.
I feel like it would help if WEIRDness were predicted by psychological theory to moderate particular effects in particular directions, which could be tested with more power than the more open-ended/uninformed question of whether it moderates any effects in any directions.
I think the biggest problem with Joe Henrich's complaint here is that he is assuming standard psychological studies are basically reasonable (that they study relevant phenomena with good methods), and that they're merely unreasonably generalized. Meanwhile I feel like a lot of the studies he complains about probably shouldn't even have been done, or at least should have been done in a much better way.
I could buy that once psychology started producing a huge stream of good research, value could be gained in making it more cross-cultural. But we're not really there yet...