
Nonhuman Intelligence
The IQs of LLMs don't mean much yet and it's not clear they ever will

This is the second in a series of posts with timed writing. If it takes me more than an hour to complete them, my text editor closes and what I’ve written so far gets deleted. The sole previous timed piece can be found here.
No one has developed a test that allows us to compare the intelligence of man and animal. There are plenty of cognitive tests available to compare different humans, but none that allow us to estimate the intellectual gap between humans and, say, chimps, much less animals whose cognitive abilities lie at a level even further below mankind.
Chimps are probably as close as we can get to a comparison between mankind and members of a nonhuman species. Hints of this possibility are observable in a 2019 paper by Kaufman, Reynolds and Kaufman where they examined the factor structure of an IQ test developed for nonhuman primates, the Primate Cognition Test Battery (PCTB).
The currently dominant intelligence test model is the Cattell-Horn-Carroll, or CHC model that developed out of John B. Carroll’s 1993 Human Cognitive Abilities: A Survey of Factor-Analytic Studies. This diagram by Timothy Bates is a good way to visualize it:
 fluid intelligence (Gf), crystallized intelligence (Gc), general memory and learning (Gy), broad visual perception (Gv), broad auditory perception (Gu), broad retrieval ability (Gr), broad cognitive speediness (Gs), and processing speed (Gt).")
As it turns out, this model from humans is roughly able to be fitted to Kaufman, Reynolds and Kaufman’s PCTB data, like so:
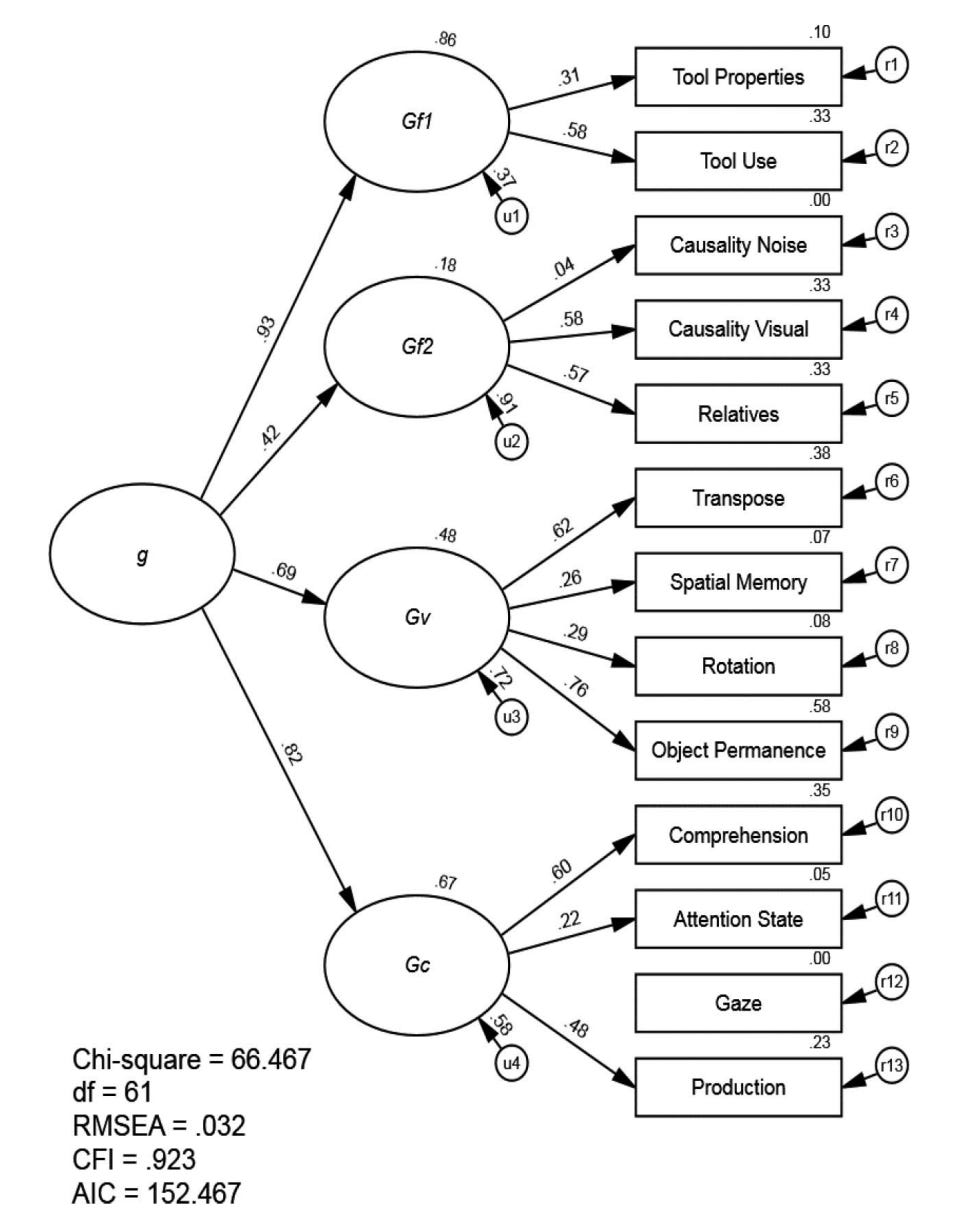
The model fits reasonably well, but if you gave this battery to adult humans, they would max out all the tests because they’re just too easy for humans; we are that far above apes. So the solution, then, is to give the battery to very young humans—preschoolers—whose abilities aren’t yet outside the range of ape intelligence.
Doing this might seem pointless though, since if we do that, we’re not comparing the levels of human and ape intelligence, so what’s the point? The point is to assess the equivalence of the structure of intelligence across species. This is why using things like memory and speed elementary cognitive tasks wouldn’t work, because the structural relations among those tests will probably vary between chimps and humans for reasons related to focus, adherence to procedure, ability to comprehend test rules, etc., which humans tend to be comparable with respect to, but which we can’t ensure chimps and humans are. Thus, the comparison won’t be about intelligence alone, like we want it to be.1
Structural comparability would have enormous implications in many domains. If it were ensured, apes would immediately become viable test subjects for nootropics; not only that, but they would also become tools for discovering nootropic candidates because we could breed apes for higher intelligence and work to discover its genetic underpinnings in only a few generations. Structural comparability across species would also speak for or against different theories of intelligence, for example, potentially militating against those that emphasize a role for culture among humans. There’s certainly more this finding would afford us, but needless to say, the analytical leverage provided by it would be immense.2
If Not Monkeys, Maybe Machines?
But what about something that’s potentially smarter than humans?
Maxim Lott has a new article ranking different LLMs by their performance on figural matrices tests. The idea? Because AIs now have human-level IQs and they’re advancing rapidly, we’re about to have human-level (or beyond) machine intelligences in our pockets, with the implication being that “the world will probably change a lot soon.”
So let’s test this. I obtained what I was told were the 26 questions from this study and gave them to Claude 3 Opus, assessed fifty times using verbally typed-out questions in Lott’s style. I then compared Claude 3 Opus’ responses to Krautter et al.’s sample. The questions variously used the following four rules:

I assessed measurement invariance with respect to a simple single-factor model based on eight different parcels of the sums of item (wrong/right or 0/1) scores. The parcels were automatically computed like so:
Responses <- select(df, starts_with("item_"))
Matrix <- cor(Responses)
NItem <- ncol(Matrix)
Names <- colnames(Matrix)
Parcels <- list()
AvgCor <- apply(Matrix, 1, mean)
Sorted_Items <- names(sort(AvgCor, decreasing = T))
Rem <- Sorted_Items
for(i in 1:6) {
Parcels[[length(Parcels) + 1]] <- head(Rem, 3)
Rem <- setdiff(Rem, head(Rem, 3))
}
for(i in 1:2) {
Parcels[[length(Parcels) + 1]] <- head(Rem, 4)
Rem <- setdiff(Rem, head(Rem, 4))
}
fpr (i in seq_along(Parcels)) {
Parcel_Names <- paste("Parcel", i)
Responses[[Parcel_Names]] <- rowSums(select(Responses, all_of(Parcels[[i]]))), na.rm = T)
}
ParcSums <- data.frame(matrix(nrow = nrow(df), ncol = length(Parcels)))
names(ParcSums) <- paste0("Parcel", seq_along(Parcels))
for (i in seq_along(Parcels)) {
Parcel_Items <- Parcels[[i]]
ParcSums[,i] <- rowSums(select(df, all_of(Parcel_Items)), na.rm = T)
}In the original data, the parcels included {item_13, item_12, item_20}, {16, 14, 22}, {15, 10, 6}, {19, 21, 24}, {25, 9, 23}, {26, 17, 3}, {18, 11, 7, 2}, {5, 8, 4, 1}. The single-factor model for these parcels, estimated with the WLSMV estimator in lavaan, fit very well, with a robust CFI of 0.998 and a robust RMSEA of 0.036. The g loadings for these parcels ranged between 0.771 and 0.901.
So then I went to apply the model to Claude’s data to assess initial model fit prior to testing a multi-group model.
Not possible. Claude’s responses were almost entirely homogeneous, so the model could not fit, as there wasn’t any variance to explain. This may be because each Claude instance should be treated as freshly retesting the same person, but regardless, this presents a methodological barrier to assessing the comparability of machine and human intelligence, though it doesn’t prove the two are necessarily incomparable.
So to hint at the comparability of human and LLM performance, I correlated the percentages correct for each item from the original study’s four different groups3 with the percentages correct from Claude’s assessment, like so:
GroupMeans <- df_ParcSums %>%
select(training_or_bot, starts_with("item_")) %>%
pivot_longer(cols = starts_with("item_"), names_to = "item", values_to = "score",
names_transform = list(item = ~factor(., levels = paste0("item_", 1:26)))) %>%
group_by(item, training_or_bot) %>%
summarize(mean_score = mean(score, na.rm = T), .groups = 'drop') %>%
pivot_wider(names_from = training_or_bot, values_from = mean_score) %>%
arrange(match(item, paste0("item_", 1:26)))
GroupMat <- cor(GroupMeans[, -1])The correlations ended up like so:

When human groups with different levels of training in figural matrix rules got questions correct, so too did the other groups. But Claude’s performance was essentially random with respect to the human groups. Different individuals’ performances were also correlated with the performances of other individuals, consistent with the common usage of strategies across individuals leading to common patterns of performance or, more simply, that questions vary in their difficulty, so there are some that more people tend to get right, and those questions are not the ones that LLMs tend to get right.
More intelligent humans tend to use strategies to answer questions which are consistent with success in answering and correlated in usage across questions. There doesn’t seem to be any evidence that Claude uses the strategies humans do so, at the very least, we have no a priori reason to believe Claude’s reasoning is driven by the same construct driving reasoning in humans.4
Invariant Correlates of Non-Invariant Measurements Are Unlikely
Say we have two groups, one who are taking a test normally and one who are taking a test after being shown its answer key. The result will be a biased comparison: the setup precludes measurement invariance because what the test will measure among the people taking the test normally (intelligence) will not be what’s measured in the group shown the answer key (memory).
If memory and intelligence don’t predict the same things, we should not expect results on the examination to predict the same things in our two different groups. If LLMs end up with a “high IQ” because they earn a high score for reasons unrelated to why humans might earn a high score, we should reason similarly that their performance won’t predict the sorts of things such scores would for humans.
Lievens, Reeve and Heggestad provided a good example to make this clear. They gave students medical college admissions exams and found that scores were initially correlated with intelligence and not with memory; in a retest, however, the correlations of scores with intelligence declined while the correlation with memory greatly increased. Moreover, it was only the initial scores that predicted 3-year GPAs. Memory and intelligence contributed differently on different occasions, and they predicted different things.
Why should LLM performance, as different as it’s likely to be from human cognition, be viewed any differently?
I suspect that, as LLMs improve at taking IQ tests, their gains will continue to be expressions of specific performance capabilities rather than true reasoning, with all the psychometric implications and non-implications that entails. When LLM “intelligence” can be shown to be akin to human intelligence, I’ll think otherwise. But, for now, it’s not at all clear how to even test that possibility.
A further problem is that there may be relevant age-related changes in the structure of cognitive abilities in both apes and humans, so an across-age comparison may not reveal anything about intelligence in, say, adult humans versus chimps of any age.
There is evidence that intelligence is general in a wide variety of species, from donkeys to lemurs to rodents to cleaner fish and various birds, and of course among primates. While this is true, it is only suggestive evidence that intelligence as it’s understood in humans is common across different species. This apparent generality may actually be due to entirely different factors than the ones observed in humans. Until our measurements improve, we just won’t know.
Stratified by figural matrix test training received.
This may be because Claude reasoned about matrix questions verbally whereas the human sample reasoned from images. To test this, I gave a sample of 36 convenience-sampled people on Discord the same questions and received comparable results, with the Discord sample’s results being correlated with the other human results and not with Claude’s (-0.08).
Looks like footnote 2 cuts out mid sentence. Curious what the rest says!
Interesting! For a (related) argument that the kind of intelligence/wisdom we associate with being human is irreducible, see https://tmfow.substack.com/p/artificial-intelligence-and-living