
Social Scientists Are Lazy
Social scientists don't test their theories even when they're fully capable of testing them. I think that's because they're just really lazy.

This was a timed post. The way these work is that if it takes me more than an hour to complete the post, an applet that I made deletes everything I’ve written so far and I abandon the post. You can find my previous timed post here.
I just saw this post from Jonathan Haidt claiming that a ‘powerful’ study showed that adolescents who increased social media use had lower cognitive performance compared to adolescents who didn’t increase their social media use.


Naturally, I opened up the paper, read it, and noticed that the model was not a causally informative one. This struck me as odd because the authors definitely had access to the ability to do within-person analyses—to use each person as their own control—to obtain a causally informative result, and they could’ve also used siblings as controls for one another. They could’ve even done both for thoroughness!
Thankfully, I have colleagues with access to this data. So, I drafted some code and pinged a model specification over to them to retest this result immediately. Now, I’ve produced those results for you. Before I show you that, let’s compare what the authors did to what I was able to do within a few minutes.
Nagata et al.’s Model: They used group-based trajectory modeling, where they classified 7,500 participants in the Adolescent Brain Cognitive Development (ABCD) cohort into three latent social media use trajectories across baseline, Year 1, and Year 2 (no/very low, low increasing, high increasing). They then regressed Year 2 cognitive scores on trajectory group dummies, controlling for baseline cognition, age, sex, race/ethnicity, household income, parent education, ADHD and depressive symptoms, non-social media screen time, and site.
Their estimand is the average adjusted difference in Year 2 cognition between trajectory groups—a between-person quantity that is conditional on observables. They can only identify a causal effect with their analysis if the covariate set captures all relevant confounders. Any unmeasured variable that correlates with both social media use and cognition—genetics, parenting quality, household cognitive stimulation, neighborhood and school quality, etc.— will bias the estimate.
My Models:
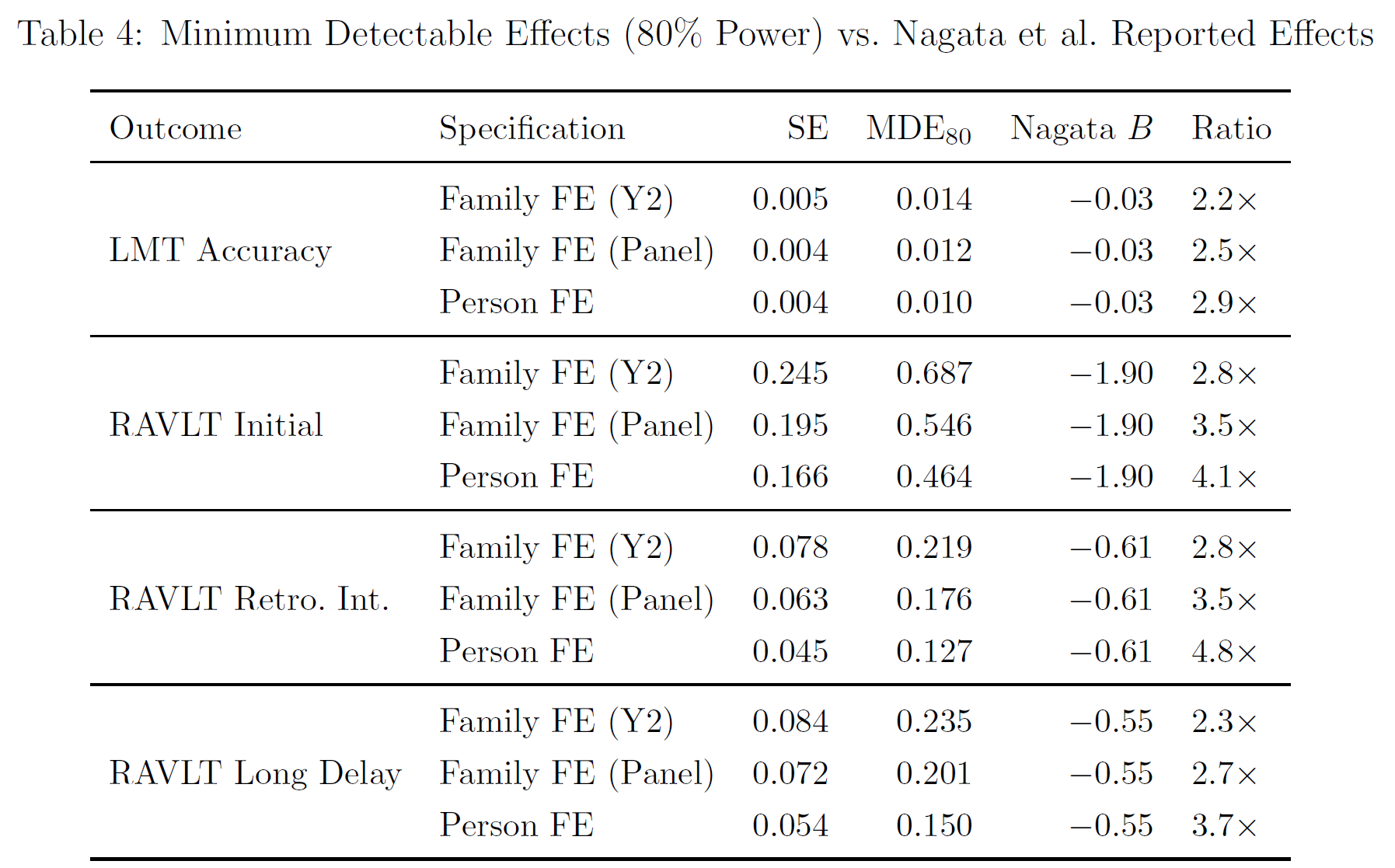
Family fixed-effects: These absorb all between-family variation by demeaning within families. The estimand is the within-family association: among siblings in the same household, does the one who uses more social media perform worse? This controls nonparametrically for everything shared within families—parental genetics, socioeconomic status, parenting style, neighborhood, school district, etc.—whether measured or unmeasured. Identification requires only that siblings’ social media use differs for reasons unrelated to their sibling-specific cognitive endowments.1
Person fixed-effects: These absorb all stable individual characteristics by demeaning within person across waves. The estimand is the within-person association: does an individual’s own increase in social media use predict their own cognitive change? This controls for everything stable about the person—their genetics, their personality, their baseline ability, their family background, etc. Identification requires that the timing of social media uptake is unrelated to time-varying individual shocks to cognitive endowments.
Panel family fixed-effects: These involve stacking both waves and demeaning within families across all person-wave observations. This is the most efficient within-family estimator because each sibling contributes two observations, increasing the variation available for identification and reducing standard errors by 9-20% relative to the cross-sectional family fixed-effects result.
I also ran negative control analyses—showing that their specification produces significant effects on outcomes that cannot possibly be affected—, I computed the minimum detectable effects across methods, I checked for nonlinearities, and I tested covariate sensitivity.
First thing’s first, I replicated their results. I was able to do that. They are not frauds.
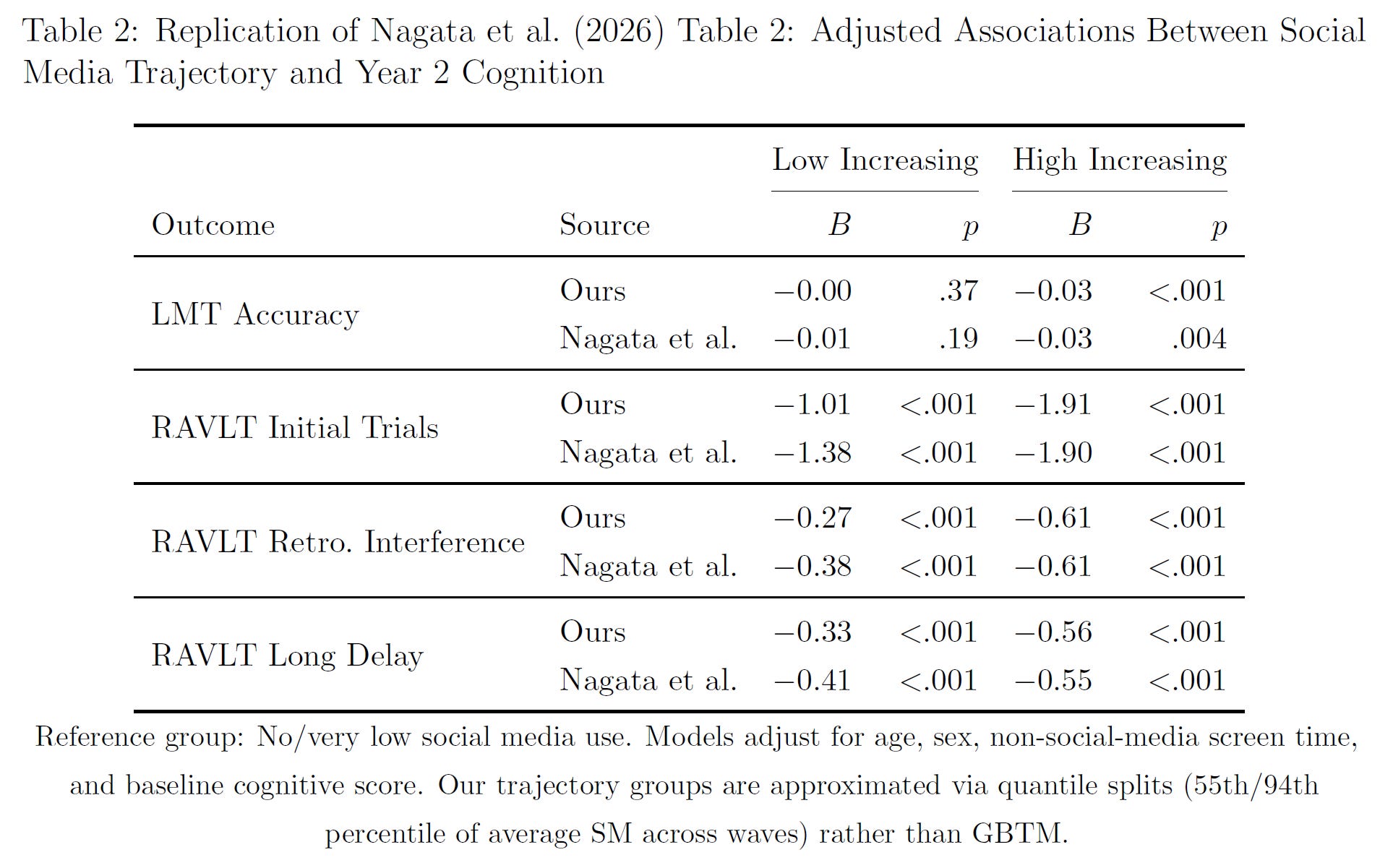
Next, I extended their results with a within-family analysis and a within-person analysis which knocked out their results and showed that they were not robust.
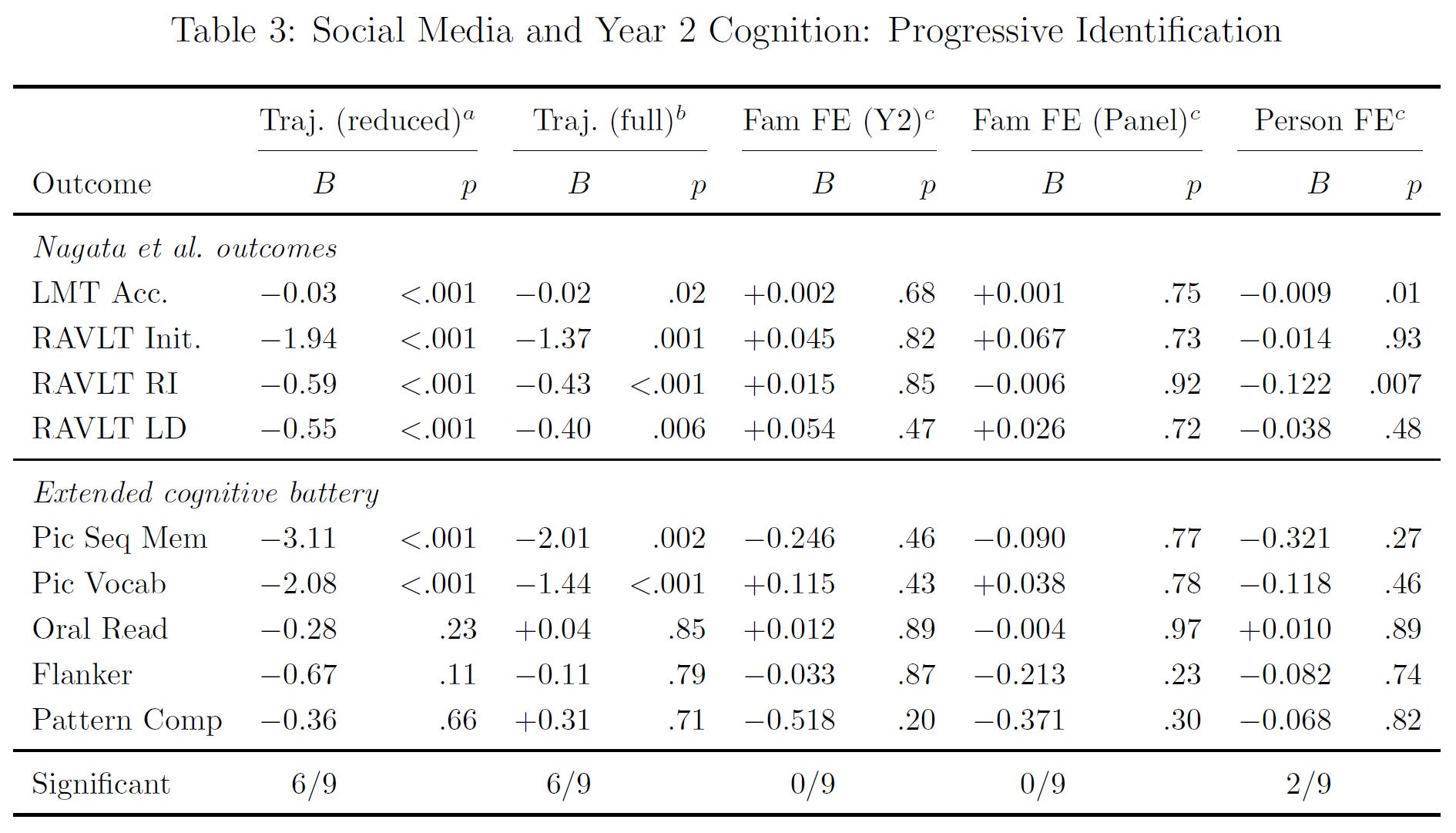
I also showed that the difference between my results and their results was not due to power, because I had more than enough power to detect smaller effects than theirs.
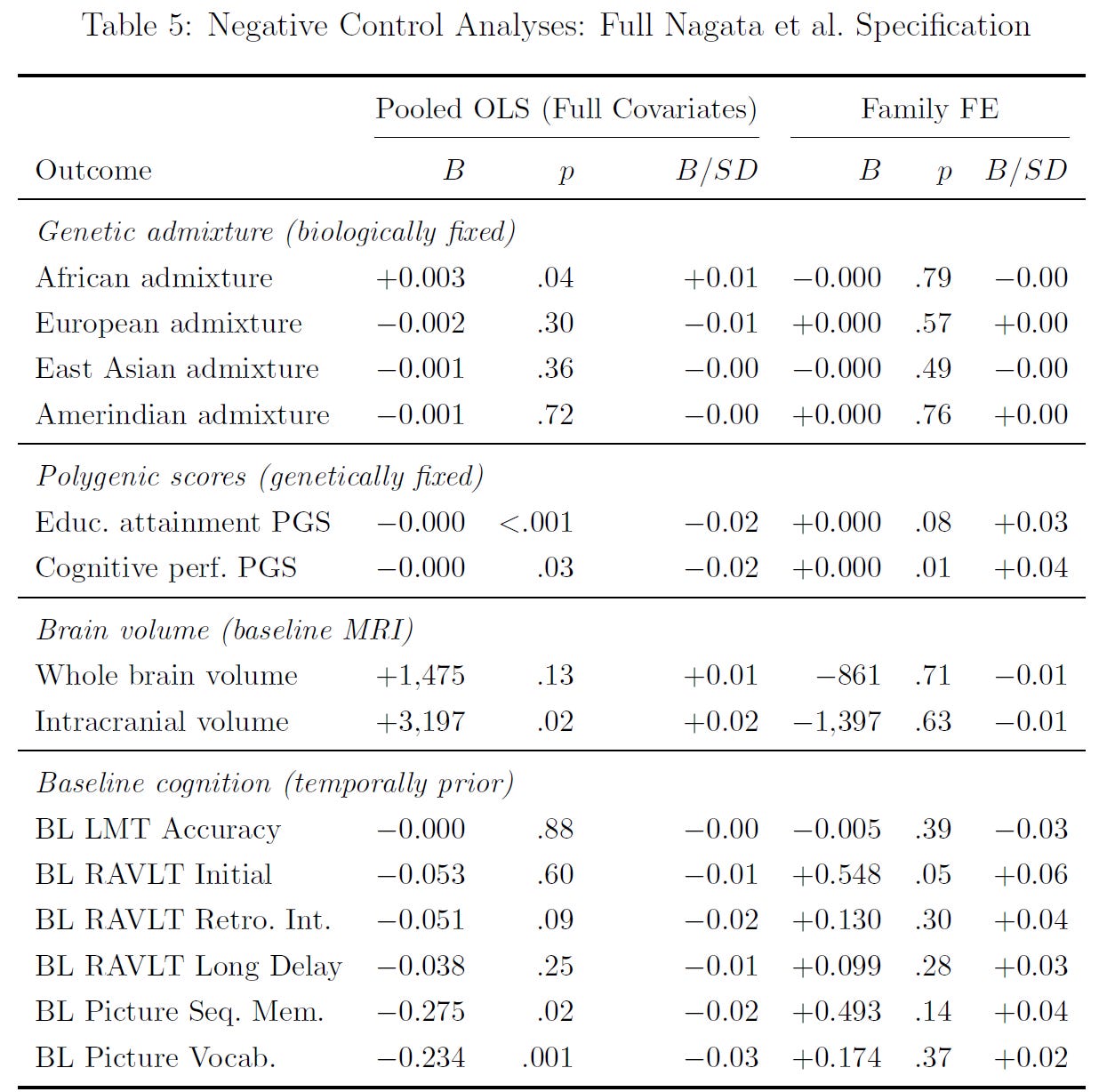
I then looked at whether their methods would suggest that social media use causes impossible outcomes: racial admixture, polygenic scores, and cognitive ability measures from earlier in time; and implausible outcomes: brain volumes. They sometimes could, but not within families!2
And to top all this off, I checked for nonlinearities in the forms of quadratic terms and categorical bins for 0, >0-0.5 hours, 0.5-1 hours, and >1 hours of social media use. Nothing was significant save for one outcome that showed a non-monotonic pattern that was inconsistent with a dose-response relationship.
And how long did it take me to find that their results didn’t hold up? Minutes.
It was trivially easy to specify and run these models and to output the results. It took practically no additional effort to go from the uninformative models used by Nagata et al. to using an actually informative model. Metallic laws, anyone?
Social Science is Always Like This
There are a lot of things that are deeply wrong with social science but, I’ll argue, none is so bad as the abject laziness with which researchers approach every subject. It took me mere minutes to correct a result that looked, to me, to be patently absurd. And let’s be frank: it is absurd. Social media does not make people less intelligent and anyone telling you it does is lying.
When you measure well, concussions don’t even lower intelligence and years of education don’t raise it. With those facts in mind, it should seem patently ridiculous to think that selecting into another hour a day of Twitter is going to make kids dull.

Nagata et al. didn’t get the right result because they’re at least one of the following: ignorant, lazy, biased, or publication farmers. They might not have known that they could test their results—ignorance. They might not have wanted to fit proper, informative models even though they knew they could—sloth. They might have wanted to make social media look bad and not cared that people could see they didn’t run appropriate models—bias. Or they might be looking to overturn their own results in a future publication, with this one intended to pad their publication and citation numbers—farming.3
Whatever their reason, Nagata et al. aren’t atypical (and I don’t want to insult them; I think calling them ignorant or lazy is descriptive and correct). Consider the issue of measurement invariance. This is a critical thing in fields where objective measurements like height and weight aren’t being used and the measurements are instead of hypothetical quantities like group perceptions, neuroticism, intelligence, or what-have-you. To compare groups or individuals across times, you have to establish that those measurements are comparable over time, and despite this possibility being routinely available to researchers, almost no one tests it, and when they do test it, they tend to test it incorrectly. Yet, if you can’t compare measurements over time or between populations, any differences might be due to that incomparability rather than due to variation in the target trait. So, why don’t researchers assess measurement invariance?
Well, they’re lazy. They’re so lazy that they rarely ever do the required robustness and sensitivity analyses to assure that their results are as they are, or to let them triangulate in on something causally informative.
The field of economics has made a lot of strides in this regard. The typical economics paper in a modern, high-tier journal is littered with tables full of robustness tests4, and these allow economists say that their results hold up. In fact, they’ve gotten so good at this that I like to cite something called Henderson’s Law: “When you read an econometrics study done after 2005, the probability that the researcher has failed to take account of an objection that a non-economist will think of is close to zero.”5


But we’re not yet at the point where the rest of the social sciences—including genetics and medicine—can confidently say the same. In fact, it’s more typical for there to be glaring errors that even laymen could spot.
I don’t know how to fix this. I imagine any fix has to be internal to a field. In economics, this was self-led based on an outcry to “Take the Con out of Econometrics”, but it was also possible because economists tend to be smart. The people in other fields tend to be considerably less intelligent and, especially, less capable at or interested in doing mathematics-heavy work, even if they’ve got plenty in terms of raw smarts. If I had to place a wager, I’d say the average sociologist, social scientist, or even medical doctor cannot write even simple proofs.6 What hope do they have to notice something like that a method such as Non-Linear Mendelian Randomization is just not workable?
Happy Note
In 2019, I gave a conference presentation that documented that methodological innovations precede theoretical improvements rather than vice-versa in the domains of differential psychology and analytical chemistry. I think those conclusions held up well, and they present the possibility that social science doesn’t have to be this way.
The fix I have in mind is to have methodologists steward their fields. The people who have a deep understanding of and desire to improve on and implement different methods are the real heroes of science, and to the extent they’re empowered, they can force compliance. Consider the issue of ‘small sample sizes’. Once people started pointing out that many samples used in the social sciences were too small to answer their questions after Ioannidis’ Why Most Published Research Findings Are False and its’ knock-on work, it became a rallying notion. Suddenly, a study could be dismissed out of hand based on a sample being too small, and lots of bad work became unpublishable!
This was by no means perfect; the complaint is often taken too far because the people brandishing the excuse to dismiss a given paper usually do so without the knowledge of what a small sample actually means. Nevertheless, this was progress. Suddenly, tons of papers that would very likely be bad died in the cradle and the number of false-positives was probably comparatively meager. And this shows us the way!

The way is this: increase the salience of methods and reduce the friction to using them. Make software packages that easily implement new methods. This will result in a proliferation of careless results—as has happened with the literature on Mendelian Randomization—but it will nevertheless improve the average quality above simpler methods and lacking checks. We also need to increase the salience of the need for assurances. Authors should be compelled by editors, reviewers, and their coauthors to check twice if they’re going to cut once; it costs effectively nothing to host a large supplement containing robustness tests, so journals should heavily encourage them.
Am I being too optimistic about this? Almost certainly. I live to be disappointed.
P.S. Did you know that the New York Times wrote a slanderous and obviously error-riddled article kvetching about me having access to this data? If not, you can go check that out here!
P.P.S. Here’s my replication code. Unfortunately, I can’t provide the data; you’ll have to apply for access to that yourself.
It’s worth noting that their analysis is basically looking at group differences, not continuous associations. In my attempts to look at continuous associations, I did not find them, undermining their claims.
Excepting the cognitive performance polygenic score, the result of which likely just reflects the causal within-family association between genes for cognitive ability and lower social media use. These results were more significant without covariates.
This seems probable given their prior, superfluous publication.
Which is not to say that those robustness tests are fair.

Henderson’s Law is obviously tongue-in-cheek.
I would not ascribe this to a lack of raw intelligence among medical doctors. For them, I’d sooner chalk this up to their lack of interest in methods and mathematics. Many of them are just off in their own world.
"It was trivially easy to specify and run these models and to output the results."
I have 3 technical degrees from MIT and don't know enough statistics to follow your explanation.
Give yourself more credit.
How about creating an LLM based tool that reads papers and flags specific or potential issues? It might not be perfect, but it could be a way to do a little stress testing at scale.