
Why Economists Detect Fraud
Most studies don't matter enough for people to determine they're fake

In the soft sciences, cases of fraud sometimes crop up for studies that have become classical, studies that are so old and so seminal that they’ve inspired thousands of knock-on studies, theories, and—without exaggeration—lakes of spilled ink. The fraud problem isn’t relegated to those fields. In harder fields like biology, there’s certainly no shortage of fraud either—go scroll Elisabeth Bik’s Twitter feed if you really need to see that fact confirmed. There are even frauds whose fraud becomes acknowledged and they don’t lose their book deals, speaking arrangements, collaborations, tenure, jobs, advisory positions, and so on. The usual outcome of doing academic fraud and having it recognized is, unfortunately, a slap on the wrist.
Fraud is a major problem across the sciences: it wastes people’s time and effort, it gives people false hopes, and it leads to theories that don’t have solid foundations. I have the distinct impression that it’s less of a problem in economics for one simple reason: If someone commits fraud in economics, it’s more likely to matter.
Plenty of economists deal with and in nonsense, but there are few examples of a field that is, overall, as directly important for policy as economics. Economists deal with substantive issues that can directly impact the policy prescriptions that governments act on. Simply put, because economists interface with the real world very rapidly and in major ways, their work is often important.
With the preface out of the way, let’s talk….
Dividend Taxation
In July of 2021, Charles Boissel and Adrien Matray brought forward a preprint in which they estimated the impact of France’s 2013 three-fold increase in the dividend tax rate on firms’ investment decisions. They used a difference-in-differences design and the comparisons from this paper were between firms that had lower and higher dividend payouts prior to the tax change. The impact of the change on dividend payments was predictable in that they declined, substantially. As the old adage goes “If you tax something, you get less of it.”

This result is about as unambiguous as you can get, it’s exactly what’s expected, and it leads to consideration of two partially competing perspectives on what should happen as a result of the change in dividend payouts. These are:
The higher the tax on dividends, the less firms will want to pay out dividends, and the more of their earnings they’ll retain, which they can use to finance investment or improve employee compensation.
The higher the tax on dividends, the higher the user cost of capital, leading to less firm investment for those firms that finance marginal investments through equity issuance and which use their investment returns to pay dividends.
The reason I’ve said these are “partially” competing perspectives is that the latter perspective tends to be something that disproportionately impacts new firms and firms with limited credit access.
Anyway, when these were put head-to-head by estimating the impact of the tax reform on investment… we got a boom! Take a look:
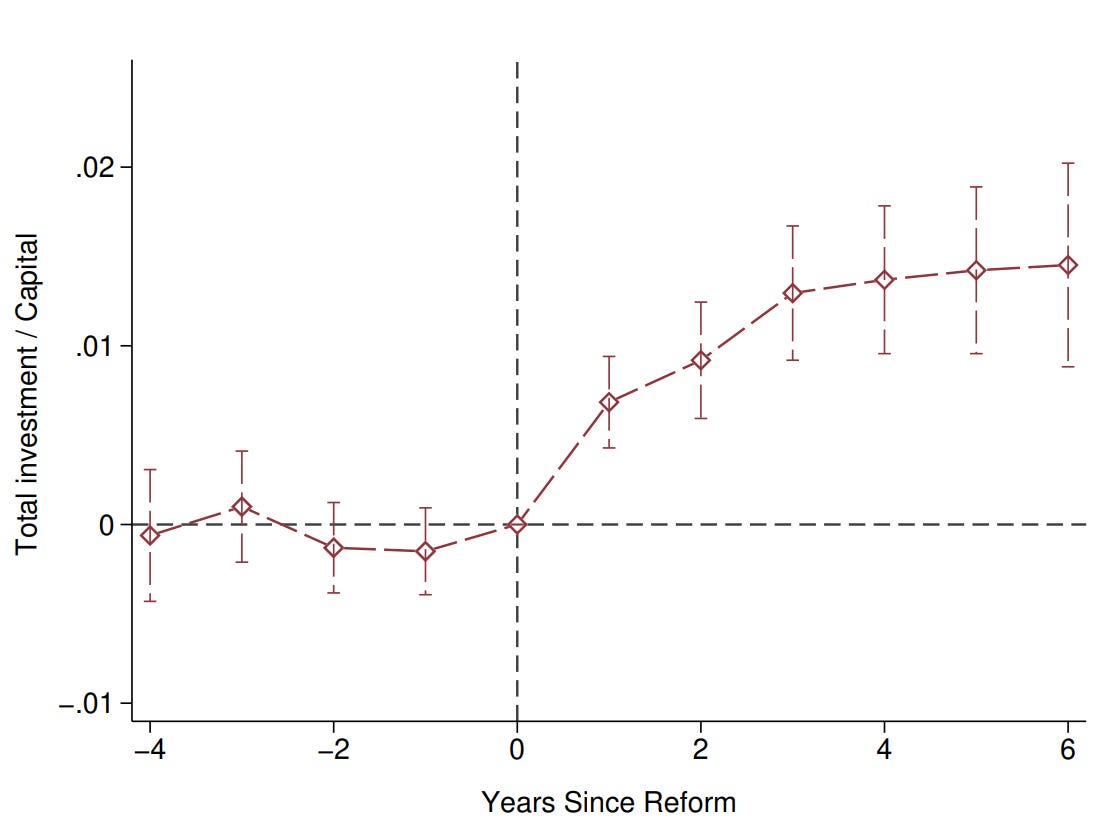
So there we have it: apparently unambiguous evidence that taxing dividends more tends to increase investment, at least at the margins seen in France. Consistent with the paper’s obvious importance, it couldn’t remain unpublished for long, and in late 2022, it officially came out in the American Economic Review (that’s a relatively fast review). And then it was retracted by mid-2023 because the result was impacted by clear-cut fraud and robustness problems.
Papers published in the American Economic Review—one of economics’ premiere journals—are supposed to include a replication package, and Boissel and Matray’s work did. The problem is that, when Bach, Bozio, Guillouzouic and Malgouyres went into that replication package looking to play around with the paper’s model, they found something… odd, to say the least. They found this mysterious code section:
// 2. Aggregate the different results
foreach Y in dK_nppe {
clear
save "$output/graph", replace emptyok
forval x =4/4{
append using "$output/`Y'_1_`x'"
rename (B SE) (B`x' SE`x')
replace B = B/1.8 if t>-3&t<0
gen B`x'inf = B`x'- 1.96*SE`x'
gen B`x'sup = B`x'+ 1.96*SE`x'
save "$output/graph",replace
}The line that should stand out is
replace B = B/1.8 if t>-3&t<0This line shrinks the pre-treatment coefficients from their plot about investment effects in order to disguise the appearance of differential pre-trends.
The issue with this is that if there’s a trend before the dividend tax hike went into effect, we would become less capable of figuring out if the change we’re looking at is due to the treatment or due to something that was already happening differently in firms offering higher or lower dividend payouts. If the treatment and the control are trending strictly parallel prior to the treatment, like in (a) below, then we’re good! If they’re converging (or diverging), like in (b) (imagine it in your head) below, then inference is harder to justify.

As the author of these graphs stated: “Finding that the trends weren’t identical doesn’t necessarily disprove that [difference-in-differences] works in your instance, but you’ll definitely have some explaining to do as to why you think that the gap from just-before to just-after treatment didn’t change even though it did change from just-just-before to just-before!”1
Boissel and Matray didn’t bother trying to explain anything about pre-trends, they just fraudulently deleted the evidence for the differential pre-trend. This is problematic enough in its own right, but it might not have totally compromised the study’s results. Looking at the plot provided by Boissel and Matray (BM) versus one without their fraudulent pre-trend division, very little is changed:

The problem with this is more of a theoretical one: because there were differential pre-trends, it is harder to justify a causal interpretation for these results, whatever they were. But the deeper problem with BM’s result has to do with the second issue, of robustness.
Robustness is closely related to the concepts of reproducibility and replicability. Here’s a simplified outline of how I think about these concepts:
Exact Reproducibility: I run your code on your data, I get your result.
Analytic Reproducibility: I run your analysis on your data, I get your result. I can use different software packages that should do the same things, and your result holds up.
Technical Reproducibility: I run your analysis on your data with different technical details like the choice of (appropriate) estimator, handling of leverage and outliers, or other differences that should only affect edge cases, and I get your result.
Robustness Reproducibility: I run close specifications to your own with your data, and I get your result. I can use different, theoretically acceptable controls, subgroups, fixed effects, etc., and if your result holds up, it’s ‘robust’.
Replicability: I redo your analysis with new data and I get your result. This breaks down further into things like exact replicability, conceptual replication with new theoretically similar or relevant designs, and more, but since reproducibility is the focus, I’ll leave this at the basics.2
Boissel and Matray’s result was not robust. Usually when a result isn’t robust, it’s because it was marginally significant (i.e., 0.05 < p < 0.01) and small alterations should tend to make p > 0.05 because authors select a rare specification among all possibilities which contains p < 0.05.3 In Boissel and Matray’s case, the result was really not robust, and the reason was that their original specification used bad controls.
Boissel and Matray tackled potential pre-trend issues by including a curious little control variable named “SizeGrowthBin_{it}”, which they defined as “a vector of pre-reform annualized size growth quartile-by-year fixed effects.”
OK, sounds good. But what does that mean?
Well, “size growth” is evidently capital growth, which is the investment rate. This means that Boissel and Matray controlled for a lagged version of their primary outcome variable. Bach, Bozio, Guillouzouic and Malgouyres (BBGM) noticed this could very well have been a problem, so they went to testing what would happen if it were addressed.
In the figure below, you can see the original, non-fraudulent version of Boissel and Matray’s specification in orange, with their very significant pre-trends. In the green, the pre-reform measurement of the outcome variable is no longer controlled and the difference in pre-trends is somewhat shrunken, so evidently the controls for pre-treatment investment were pre-trend reinforcing, making regression to the mean a problem. BBGM also noted that this pre-treatment outcome control forces pre-trends to be parallel “and is akin to assuming conditional independence rather than parallel trends for identification. Yet, under such reasoning, a specification without controls would display more significant differential pre-trends rather than less as is the case here.”
Boissel and Matray’s choice of control was clearly not reasonable for their design, and fixing it, the tax change effect on investment is more ambiguous and clearly smaller. But we’re not done because we’re missing a more reasonable control: a control for firms’ levels of total capital, which is totally warranted for two reasons. Firstly, it’s warranted since it’s really not reasonable to expect larger and smaller firms to proportionally change their investments. Secondly, it’s reasonable because treated firms are smaller! With a size control, you get the ruddy red specification shown below, with differential pre-trends and possible negative effects on investment!

Boissel and Matray’s result included an element of fraud and was not robust, but to top it all off, Boissel and Matray lied to the editor at the American Economic Review. They said their specification they presented results for was the red one in the chart above, not the one they actually presented, which controlled for a lagged version of the outcome and lacked a size control. Quoting BBGM:
Indeed, the current editor informed us that this is the baseline specification as described by BM in the version of their paper that the reviewers saw and that the handling coeditor accepted for publication conditional on compliance with the AEA’s Data and Code Availability Policy. Yet, this third specification does not deliver clearer results, as differential pre-trends are very significant in the opposite direction, possibly because high levels of capital in rather young firms reflect recent investments and hence predict lower future investment due to mean reversion.
The result we end up with all said and done? Ambiguous. Who can really say?
Why Was This Caught?
Dividend taxation matters. If governments want to implement, increase, or decrease a dividend tax, policymakers will need papers to cite on the matter to justify changes. If all the evidence points in the direction of higher taxes being better for investment, then policymakers could readily cite that evidence as a justification and we might end up with higher dividend taxes. But, if results are ambiguous—as they appear to be—then pursuing changes in dividend taxation is more about policymakers’ own predicted policy effects rather than empirically-supported predictions of policy effects. Ambiguity leaves more room for political argument about impacts, and makes it harder to favor pro or con positions on the matter as being obviously good or obviously bad for an outcome like firms’ investment decisions and the health of the broader economy.
Since this issue is important, economists noticed the paper, looked through the replication materials, and contacted the editor, leading them to find that the paper involved
Obvious fraud
Dubious model specifications
Lying to the editor and reviewers
For any of those reason, the study should have been retracted; it just so happens it was retracted for all of those reasons. So at least in this case, economics was self-correcting, at least in an area that has real world importance. But, were it not for the mixture of
Policy importance
Data and code availability
Editorial openness
this fraud wouldn’t have been caught, or at least wouldn’t have been caught so quickly.
Since the Boissel and Matray paper was policy-relevant, the world is lucky that the AEA has a “Data and Code Availability Policy” and that policy-relevance begets critical interest. If those things weren’t true, it could have taken much longer to realize something was wrong, and the realization might have come in the form not of an investigation of the original paper, but as replication failures.
Policymakers could have ended up citing Boissel and Matray’s paper and had to realize the hard way that bad science leads to bad policy that can hurt real people if the result didn’t hold up (and since it’s ambiguous, we have no idea what to expect).
To make matters worse, replication failures could have begat the need to do more research, so this fraud could have led to needlessly spilled ink, and senseless empirical debates about what’s really true, why Boissel and Matray got different results than other work, and so on. We could be treating Boissel and Matray like a fraudulent version of Card and Krueger and talking about it for years. Hopefully, now it just fades away.
What’s Going To Happen To Boissel and Matray?
The ideal comeuppance for academic frauds is excommunication from their academic fields, and—ideally—any academic field. The simple fact is that is you commit fraud, it casts a shadow over all your work. To avoid burdening others with the reality of their lack of trustworthiness, frauds should leave their fields. What happens after that? I don’t know, but they cannot stay.
My suggestion for outed frauds is to get on doing something tangible. It doesn’t have to be digging ditches. You could be a trader, or a carpenter, or someone who does something that is unambiguously not fraudulent and doesn’t require the public to put its trust in you for important decisions. Once that trust is violated, there is simply no other way.
But what’s actually happened in this case is unfortunately not that great. Firstly, Matray and Boissel got to write a reply to the retraction saying that their conclusions weren’t affected by the issues identified by BBGM and that their fraudulent alterations to pre-treatment coefficients were just an error and not a deliberate manipulation. They had the right of reply and they decided to use it to lie rather than to apologize. Tactful!
Long after the fraud was revealed, Matray was allowed to co-organize the Einaudi Finance Conference at Einaudi Institute for Economics and Finance in Rome from June 4-5, a session on Trade and Finance at Stanford from July 25-26, and now Matray is a visiting scholar in the Harvard Department of Economics for the year 2024-25, and he retains his affiliations with NBER and CEPR.
Matray remains in academia, unfortunately, and he doesn’t seem to have received much punishment for brazenly committing fraud.4 Now, Charles Boissel on the other hand is no longer in academia. Boissel seemingly left before the fraud became apparent, and he claims that he was not part of the project when the fraud was committed. Boissel also did not appear on the response to the retraction; the only author officially on that was Matray.
Given Matray alone brazenly lied in the response to the retraction and called the deliberate reduction of coefficients a “mistake” rather than admitting to what it actually was, I strongly lean towards believing Boissel’s story about not being responsible. Matray really showed out here, in a bad way.
In any case, it seems what’s happened to these authors is not evident beyond the retraction of their bad paper. The seeming lack of punishment from the economic profession is worrying, even if the retraction is heartening.
This is not a one-off; this happens relatively frequently in economics.5 We know from evidence like image duplication in biology and chemistry that those fields also have plenty of fraud, so the fact that fraud retraction happens fairly often in economics isn’t necessarily a black mark indicating high rates of fraud in the field—all signs suggest we should think ‘far from it’. As I’ll contend, this indicates that economics has a high rate of fraud detection and handling, at least where it matters.6
I think the lesson for other fields is clear. If you want to catch fraud, do work that people care about, whether that’s because it’s interesting or because it affects real people, and make it possible to check for bad work, like the AEA did by requiring these authors to upload their replication package. Maybe then science can become more like economics: self-correcting.
I don’t want to belabor this post by talking about difference-in-differences methods, how to deal with the parallel trends assumption, or anything else like that, so my recommendation if you’re interested in that is to read the book chapter linked below that graph. Also buy the book. Its author, Nick, is a good guy.
I would also like to advance a concept a colleague came up with: Social Science Reproducibility.
This colleague defined it as “I run your code twice and get two different results.” Noting that “a fair number of compilers actually have Social Science Reproducibility, and yes, there is no justifiable theoretical reason for this and it’s… as stupid as it sounds. The Haskell compiler is [an example]. And yes, this has security implications. This is one of those areas where doing the stupid thing is so ubiquitous [that] we had to invent a special new word for doing the obvious thing that actually makes sense.”
That word? Reproducible builds!
This can be thought of distributionally.
For a given independent variable and dependent variable in some dataset, the distribution of p-values for regressions will be centered around some value across different plausible specifications. Authors seeking to get published are biased towards significance and will thus tend to choose to display results where the focal result has p < 0.05, or whatever the threshold happens to be. For example, it is sometimes 0.10, and people sometimes choose to make their test one-tailed if it helps them pass the threshold, even if those are numerically few among plausible specifications available to them for testing. Specification curves/multiverse testing lay this bare, and they reveal why shifting from, say, p = 0.04 to p = 0.07 can have strong implications about a result’s replication probability even if a result remains nearly-significant: the tests with one dataset are dependent and so shouldn’t change that much, but replications will tend to be even less extreme, so if you can’t hold up in one dataset, lower the odds replication will be successful.
In the counterfactual world where they weren’t caught, maybe Matray is doing better right now. I can’t speak to that, I can only speak to what seems to be.
And it’s not just relegated to fraud detection, but to error detection more generally. Consider, for example, the Reinhart and Rogoff saga.
Fields that definitely make advances, like meteorology, also lack much fraud and correct fraud and errors quickly. The feedback from reality that they have is more common in fields that are harder. Economics’ fraud detection is unique in that it applies to a social scientific field.
Thanks for the shoutout!
Economics is certainly better at this than the social sciences but this made me think of Bryan Caplans article about how virtually no one actually looked at his data: https://www.betonit.ai/p/no-one-cared-about-my-spreadsheets?r=24ib7&utm_campaign=post&utm_medium=web